 |
|
МЕНЮФестивали и конкурсы Семинары Издания О МОДНТ Приглашения Поздравляем НАУЧНЫЕ РАБОТЫ |
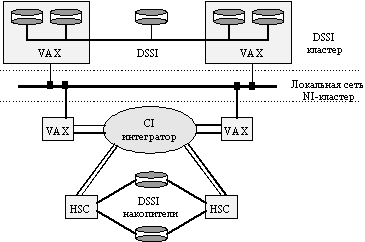
Реферат: Кластерные системыКластеры могут иметь разделяемую память на внешних дисках, как правило, на дисковом массиве RAID. Дисковый массив RAID — это серверная подсистема ввода- вывода для хранения данных большого объема. В массивах RAID значительное число дисков относительно малой емкости используется для хранения крупных объемов данных, а также для обеспечения более высокой надежности и избыточности. Подобный массив воспринимается компьютером как единое логическое устройство. Восстановление после сбоев может поддерживаться как для узла в целом, так и для отдельных его компонентов — приложений, дисковых томов и т.д. Эта функция автоматически инициируется в случае системного сбоя, а также может быть запущена администратором, если ему, например, необходимо отключить один из узлов для реконфигурации. Узлы кластера контролируют работоспособность друг друга и обмениваются специфической «кластерной» информацией, например, о конфигурации кластера, а также передавать данные между разделяемыми накопителями и координировать их использование. Контроль работоспособности осуществляется с помощью специального сигнала, который узлы кластера передают друг другу, для того чтобы подтвердить свое нормальное функционирование. Прекращение подачи сигналов с одного из узлов сигнализирует кластерному программному обеспечению о произошедшем сбое и необходимости перераспределить нагрузку на оставшиеся узлы. В качестве примера рассмотрим отказоустойчивый кластер VAX/VMS. Кластера VAX/VMSКомпания DEC первой анонсировала концепцию кластерной системы в 1983 году, определив ее как группу объединенных между собой вычислительных машин, представляющих собой единый узел обработки информации. По существу VAX-кластер представляет собой слабосвязанную многомашинную систему с общей внешней памятью, обеспечивающую единый механизм управления и администрирования. VAX-кластер обладает следующими свойствами: Разделение ресурсов. Компьютеры VAX в кластере могут разделять доступ к общим ленточным и дисковым накопителям. Все компьютеры VAX в кластере могут обращаться к отдельным файлам данных как к локальным. Высокая готовность. Если происходит отказ одного из VAX-компьютеров, задания его пользователей автоматически могут быть перенесены на другой компьютер кластера. Если в системе имеется несколько контроллеров HSC и один из них отказывает, другие контроллеры HSC автоматически подхватывают его работу. Высокая пропускная способность. Ряд прикладных систем могут пользоваться возможностью параллельного выполнения заданий на нескольких компьютерах кластера. Удобство обслуживания системы. Общие базы данных могут обслуживаться с единственного места. Прикладные программы могут инсталлироваться только однажды на общих дисках кластера и разделяться между всеми компьютерами кластера. Расширяемость. Увеличение вычислительной мощности кластера достигается подключением к нему дополнительных VAX-компьютеров. Дополнительные накопители на магнитных дисках и магнитных лентах становятся доступными для всех компьютеров, входящих в кластер. Работа VAX-кластера определяется двумя главными компонентами. Первым компонентом является высокоскоростной механизм связи, а вторым - системное программное обеспечение, которое обеспечивает клиентам прозрачный доступ к системному сервису. Физически связи внутри кластера реализуются с помощью трех различных шинных технологий с различными характеристиками производительности. Основные методы связи в VAX-кластере представлены на рис. 4.
Рис. 4 VAX/VMS-кластер Шина связи компьютеров CI (Computer Interconnect) работает со скоростью 70 Мбит/с и используется для соединения компьютеров VAX и контроллеров HSC с помощью коммутатора Star Coupler. Каждая связь CI имеет двойные избыточные линии, две для передачи и две для приема, используя базовую технологию CSMA, которая для устранения коллизий использует специфические для данного узла задержки. Максимальная длина связи CI составляет 45 метров. Звездообразный коммутатор Star Coupler может поддерживать подключение до 32 шин CI, каждая из которых предназначена для подсоединения компьютера VAX или контроллера HSC. Контроллер HSC представляет собой интеллектуальное устройство, которое управляет работой дисковых и ленточных накопителей. Компьютеры VAX могут объединяться в кластер также посредством локальной сети Ethernet, используя NI - Network Interconnect (так называемые локальные VAX-кластеры), однако производительность таких систем сравнительно низкая из-за необходимости делить пропускную способность сети Ethernet между компьютерами кластера и другими клиентами сети. Также кластера могут стоиться на основе шины DSSI (Digital Storage System Interconnect). На шине DSSI могут объединяться до четырех компьютеров VAX нижнего и среднего класса. Каждый компьютер может поддерживать несколько адаптеров DSSI. Отдельная шина DSSI работает со скоростью 4 Мбайт/с (32 Мбит/с) и допускает подсоединение до 8 устройств. Поддерживаются следующие типы устройств: системный адаптер DSSI, дисковый контроллер серии RF и ленточный контроллер серии TF. DSSI ограничивает расстояние между узлами в кластере 25 метрами. Системное программное обеспечение VAX-кластеров Для гарантии правильного взаимодействия процессоров друг с другом при обращениях к общим ресурсам, таким, например, как диски, компания DEC использует распределенный менеджер блокировок DLM (Distributed Lock Manager). Очень важной функцией DLM является обеспечение когерентного состояния дисковых кэшей для операций ввода/вывода операционной системы и прикладных программ. Например, в приложениях реляционных СУБД DLM несет ответственность за поддержание согласованного состояния между буферами базы данных на различных компьютерах кластера. Задача поддержания когерентности кэш-памяти ввода/вывода между процессорами в кластере подобна задаче поддержания когерентности кэш-памяти в сильно связанной многопроцессорной системе, построенной на базе некоторой шины. Блоки данных могут одновременно появляться в нескольких кэшах и если один процессор модифицирует одну из этих копий, другие существующие копии не отражают уже текущее состояние блока данных. Концепция захвата блока (владения блоком) является одним из способов управления такими ситуациями. Прежде чем блок может быть модифицирован должно быть обеспечено владение блоком. Работа с DLM связана со значительными накладными расходами. Накладные расходы в среде VAX/VMS могут быть большими, требующими передачи до шести сообщений по шине CI для одной операции ввода/вывода. Накладные расходы могут достигать величины 20% для каждого процессора в кластере. Высокопроизводительные кластерыПринципы построенияАрхитектура высокопроизводительных кластеров появилась как развитие принципов построения систем MPP на менее производительных и массовых компонентах, управляемых операционной ситемой общего назначения. Кластеры также как и MPP системы состоят из слабосвязанных узлов, которые могут быть как однородными, так и, в отличие от MPP, различными или гетерогенными. Особое внимание при проектировании высокопроизводительной кластерной архутектуры уделяется обеспечению высокой эффективности коммуникационной шины, связывающей узлы кластера. Так как в кластерах нередко применяются массовые относительно низкопроизводительные шины, то приходится принимать ряд мер по исключению их низкой пропускной способности на производительность кластеров и организацию эффективного распараллеливания в кластере. Так например пропускная способность одной из самых высокоскоростных технологий Fast Ethernet на порядки ниже, чем у межсоединений в современных суперкомпьютерах МРР-архитектуры. Для решения проблем низкой производительности сети применяют несколько методов: - кластер разделяется на несколько сегментов, в пределах которых узлы соединены высокопроизводительной шиной типа Myrinet, а связь между узлами разных сегментов осуществляется низкопроизводительными сетями типа Ethernet/Fast Ethernet. Это позволяет вместе с сокращением расходов на коммуникационную среду существенно повысить производительность таких кластеров при решении задач с интенсивным обменом данными между процессами. - применение так называемого «транкинга», т.е. объединение нескольких каналов Fast Ethernet в один общий скоростной канал, соединяющий несколько коммутаторов. Очевидным недостатком такого подхода является «потеря» части портов, задействованных в межсоединении коммутаторов. - для повышения производительности создаются специальные протоколы обмена информацией по таким сетям, которые позволяют более эффективно использовать пропускную способность каналов и снимают некоторые ограничения накладываемые стандартными протоколами (TCP/IP,IPX). Такой метод часто используют в ситемах класса Beowulf. Основным качеством, которым должен обладать высокопроизводительный кластер являтся горизонтальная масштабируемость, так как одним из главных преимуществ, которые предоставляет кластерная архитектура является возможность наращивать мощность существующей системы за счет простого добавления новых узлов в систему. Причем увеличение мощности происходит практически пропорционально мощности добавленных ресурсов и может производиться без остановки системы во время ее функционирования. В системах с другой архитектурой (в частности MPP) обычно возможна только вертикальная масштабируемость: добавление памяти, увеличение числа процессоров в многопроцессорных системах или добавление новых адаптеров или дисков. Оно позволяет временно улучшить производительность системы. Однако в системе будет установлено максимальное поддерживаемое количество памяти, процессоров или дисков, системные ресурсы будут исчерпаны, и для увеличеия производительности придется создавать новую систему или существенно перерабатывать старую. Кластерная система также допускает вертикальную масштабируемость. Таким образом, за счет вертикального и горизонтального масштабирования кластерная модель обеспечивает большую гибкость и простоту увеличения производительности систем. Проект BeowulfBeowulf - это скандинавский эпос, повествующий о событиях VII - первой трети VIII века, участником которых является одноименный герой, прославивший себя в сражениях. Одним из примеров реализации кластерной системы такой структуры являются кластеры Beowulf. Проект Beowulf объединил около полутора десятков организаций (главным образом университетов) в Соединенных Штатах. Ведущие разработчики проекта - специалисты агентства NASA. В данном виде кластеров можно выделить следующие основные особенности: - кластер Beowulf состоит из нескольких отдельных узлов, объединенных в общую сеть, общие ресурсы узлами кластера не используются; - оптимальным считается построение кластеров на базе двухпроцессорных SMP систем; - для уменьшения накладных расходов на взаимодействие между узлами применяют полнодуплексный 100 MB Fast Ethernet (реже используют SCI), создают несколько сетевых сегментов или соединяют узлы кластера через коммутатор; - в качестве программного обеспечения применяют ОС Linux, и бесплатно распространяемые коммуникационные библиотеки (PVM и MPI); Также История проекта BeowulfПроект начался летом 1994 года в научно-космическом центре NASA - Goddard Space Flight Center (GSFC), точнее в созданном на его основе CESDIS (Center of Excellence in Space Data and Information Sciences). Первый Beowulf-кластер был создан на основе компьютеров Intel архитектуры под ОС Linux. Это была система, состоящая из 16 узлов (на процессорах 486DX4/100MHz, 16MB памяти и 3 сетевых адаптера на каждом узле, 3 "параллельных" Ethernet-кабеля по 10Mbit). Он создавался как вычислительный ресурс проекта "Earth and Space Sciences Project" (ESS). Далее в GSFC и других подразделениях NASA были собраны другие, более мощные кластеры. Например, кластер theHIVE (Highly-parallel Integrated Virtual Environment) содержит 64 узла по 2 процессора Pentium Pro/200MHz и 4GB памяти в каждом, 5 коммутаторов Fast Ethernet. Общая стоимость этого кластера составляет примерно $210 тыс. В рамках проекта Beowulf был разработан ряд высокопроизводительных и специализированных сетевых драйверов (в частности, драйвер для использования нескольких Ethernet-каналов одновременно). Архитектура BeowulfУзлы кластера. Это или однопроцессорные ПК, или SMP-сервера с небольшим числом процессоров (2-4, возможно до 6). По некоторым причинам оптимальным считается построение кластеров на базе двухпроцессорных систем, несмотря на то, что в этом случае настройка кластера будет несколько сложнее (главным образом потому, что доcтупны относительно недорогие материнские платы для 2 процессоров Pentium II/III). Стоит установить на каждый узел 64-128MB оперативной памяти (для двухпроцессорных систем 64-256MB). Одну из машин следует выделить в качестве центральной (головной) куда следует установить достаточно большой жесткий диск, возможно более мощный процессор и больше памяти, чем на остальные (рабочие) узлы. Имеет смысл обеспечить (защищенную) связь этой машины с внешним миром. При комплектации рабочих узлов вполне возможно отказаться от жестких дисков - эти узлы будут загружать ОС через сеть с центральной машины, что, кроме экономии средств, позволяет сконфигурировать ОС и все необходимое ПО только 1 раз (на центральной машине). Если эти узлы не будут одновременно использоваться в качестве пользовательских рабочих мест, нет необходимости устанавливать на них видеокарты и мониторы. Возможна установка узлов в стойки (rackmounting), что позволит уменьшить место, занимаемое узлами, но будет стоить несколько дороже. Возможна организация кластеров на базе уже существующих сетей рабочих станций, т.е. рабочие станции пользователей могут использоваться в качестве узлов кластера ночью и в выходные дни. Системы такого типа иногда называют COW (Cluster of Workstations). Количество узлов следует выбирать исходя из необходимых вычислительных ресурсов и доступных финансовых средств. Следует понимать, что при большом числе узлов придется также устанавливать более сложное и дорогое сетевое оборудование. Сеть Основные типы локальных сетей, задействованные в рамках проекта Beowulf, - это Gigabit Ethernet, Fast Ethernet и 100-VG AnyLAN. В простейшем случае используется один сегмент Ethernet (10Mbit/sec на витой паре). Однако дешевизна такой сети, вследствие коллизий оборачивается большими накладными расходами на межпроцессорные обмены; а хорошую производительность такого кластера следует ожидать только на задачах с очень простой параллельной структурой и при очень редких взаимодействиях между процессами (например, перебор вариантов). Для получения хорошей производительности межпроцессорных обменов используют полнодуплексный Fast Ethernet на 100Mbit/sec. При этом для уменьшения числа коллизий или устанавливают несколько "параллельных" сегментов Ethernet, или соединяют узлы кластера через коммутатор (switch). Более дорогостоящим, но также популярным вариантом являются использование коммутаторов типа Myrinet (1.28Gbit/sec, полный дуплекс). Менее популярными, но также реально используемыми при построении кластеров сетевыми технологиями являются технологии сLAN, SCI и Gigabit Ethernet. Иногда для связи между узлами кластера используют параллельно несколько физичеких каналов связи - так называемое «связывание каналов» (channel bonding), которое обычно применяется для технологии Fast Ethernet. При этом каждый узел подсоединяется к коммутатору Fast Ethernet более чем одним каналом. Чтобы достичь этого, узлы оснащаются либо несколькими сетевыми платами, либо многопортовыми платами Fast Ethernet. Применение связывания каналов в узлах под управлением ОС Linux позволяет организовать равномерное распределение нагрузки приема/передачи между соответствующими каналами. Системное ПООперационная система. Обычно используется система Linux в версиях, специально оптимизированных под распределенные параллельные вычисления. Была проведена доработку ядра Linux 2.0. В процессе построения кластеров выяснилось, что стандартные драйверы сетевых устройств в Linux весьма неэффективны. Поэтому были разработаны новые драйверы, в первую очередь для сетей Fast Ethernet и Gigabit Ethernet, и обеспечена возможность логического объединения нескольких параллельных сетевых соединений между персональными компьютерами (аналогично аппаратному связыванию каналов) , что позволяет из дешевых локальных сетей, обладающих низкой пропускной способностью, соорудить сеть с высокой совокупной пропускной способностью. Как и в любом кластере, на каждом узле кластера исполняется своя копия ядра ОС. Благодаря доработкам обеспечена уникальность идентификаторов процессов в рамках всего кластера, а не отдельных узлов. Коммуникационные библиотеки. Наиболее распространенным интерфейсом параллельного программирования в модели передачи сообщений является MPI. Рекомендуемая бесплатная реализация MPI - пакет MPICH, разработанный в Аргоннской Национальной Лаборатории. Для кластеров на базе коммутатора Myrinet разработана система HPVM, куда также входит реализация MPI. Для эффективной организации параллелизма внутри одной SMP-cистемы возможны два варианта:
После установки реализации MPI имеет смысл протестировать реальную производительность сетевых пересылок. Кроме MPI, есть и другие библиотеки и системы параллельного программирования, которые могут быть использованы на кластерах. Пример реализации кластера Beowulf - AvalonВ 1998 году в Лос-аламосской национальной лаборатории астрофизик Michael Warren и другие ученые из группы теоретической астрофизики построили суперкомпьютер Avalon, который представляет из себя Beowulf -кластер на базе процессоров DEC Alpha/533MHz. Avalon первоначально состоял из 68 процессоров, затем был расширен до 140. В каждом узле установлено 256MB оперативной памяти, EIDE-жесткий диск на 3.2GB, сетевой адаптер от Kingston (общая стоимость узла - $1700). Узлы соединены с помощью 4-х 36-портовых коммутаторов Fast Ethernet и расположенного "в центре" 12-портового коммутатора Gigabit Ethernet от 3Com. Общая стоимость Avalon - $313 тыс., а его производительность по LINPACK (47.7 GFLOPS) позволила ему занять 114 место в 12-й редакции списка Top500 (рядом с 152-процессорной системой IBM SP2). 70-процессорная конфигурация Avalon по многим тестам показала такую же производительность, как 64-процессорная система SGI Origin2000/195MHz стоимость которой превышает $1 млн. В настоящее время Avalon активно используется в астрофизических, молекулярных и других научных вычислениях. На конференции SC'98 создатели Avalon представили доклад, озаглавленный "Avalon: An Alpha/Linux Cluster Achieves 10 Gflops for $150k" и заслужили премию по показателю цена/производительность ("1998 Gordon Bell Price/Performance Prize"). |
Приглашения09.12.2013 - 16.12.2013 Международный конкурс хореографического искусства в рамках Международного фестиваля искусств «РОЖДЕСТВЕНСКАЯ АНДОРРА»09.12.2013 - 16.12.2013 Международный конкурс хорового искусства в АНДОРРЕ «РОЖДЕСТВЕНСКАЯ АНДОРРА»
|


Copyright © 2012 г.
При использовании материалов - ссылка на сайт обязательна.